Completed
- Fixing Attention Calculation: 13:21
Class Central Classrooms beta
YouTube videos curated by Class Central.
Classroom Contents
What is the Transformers' Context Window in Deep Learning and How to Make it Long
Automatically move to the next video in the Classroom when playback concludes
- 1 - Introduction: 0:00
- 2 - Why more context is good: 0:33
- 3 - R1 longer context: 1:06
- 4 - A little retrieval test: 1:56
- 5 - Needle-in-a-haystack: 2:40
- 6 - Multi-Round Needle-in-a-haystack: 3:38
- 7 - Machine Translation from One Book MTOB: 4:52
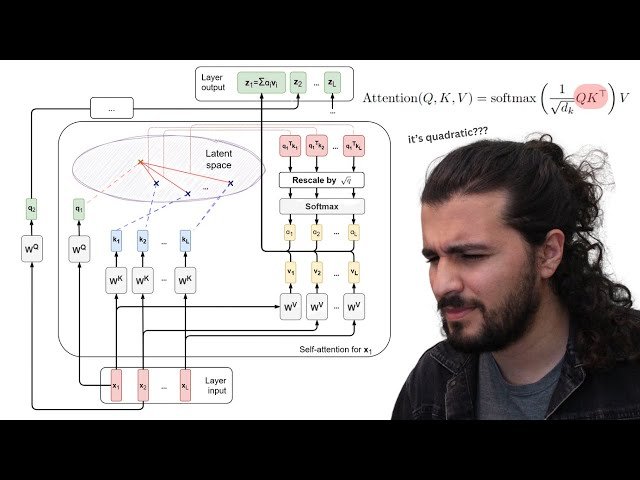
- 8 - Attention Calculation Recap: 6:16
- 9 - How to encode positions: 8:51
- 10 - Issue with increasing context: 10:07
- 11 - How to extend context: 11:26
- 12 - Fixing positional encoding: 11:45
- 13 - Fixing Attention Calculation: 13:21
- 14 - Flash Attention: 13:55
- 15 - Sparse Attention: 14:52
- 16 - Low-Rank Decomposition: 18:14
- 17 - Chunking: 19:51
- 18 - Other type of strategy using linear components: 21:44
- 19 - LLama 4 changes: 24:12
- 20 - Google Long Context Team Nikolay Savinov: 25:33
- 21 - see you folks! : 26:50
