Completed
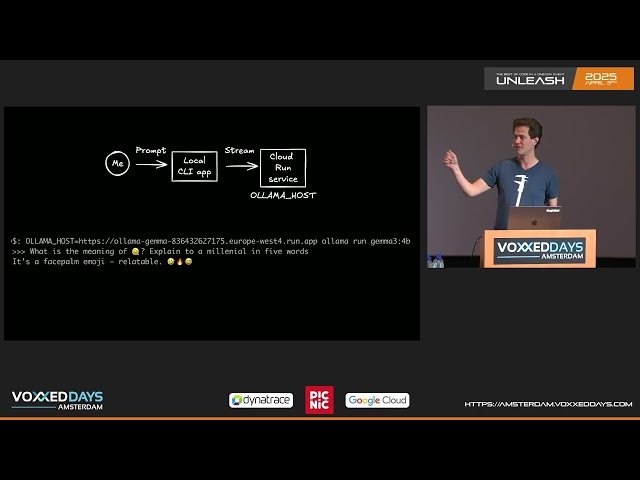
Scale to 0 LLM inference: Cost efficient open model deployment on serverless GPUs by Wietse Venema
Class Central Classrooms beta
YouTube videos curated by Class Central.
Classroom Contents
Scale to 0 LLM Inference: Cost Efficient Open Model Deployment on Serverless GPUs
Automatically move to the next video in the Classroom when playback concludes
