Completed
Keynote Talk 1: Chelsea Finn, Stanford University
Class Central Classrooms beta
YouTube videos curated by Class Central.
Classroom Contents
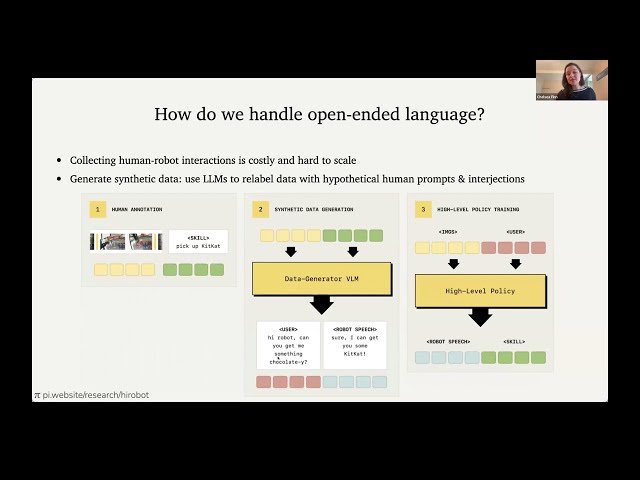
Developing Steerable, Generalizable Vision-Language-Action Models
Automatically move to the next video in the Classroom when playback concludes
