Completed
- Introduction:
Class Central Classrooms beta
YouTube videos curated by Class Central.
Classroom Contents
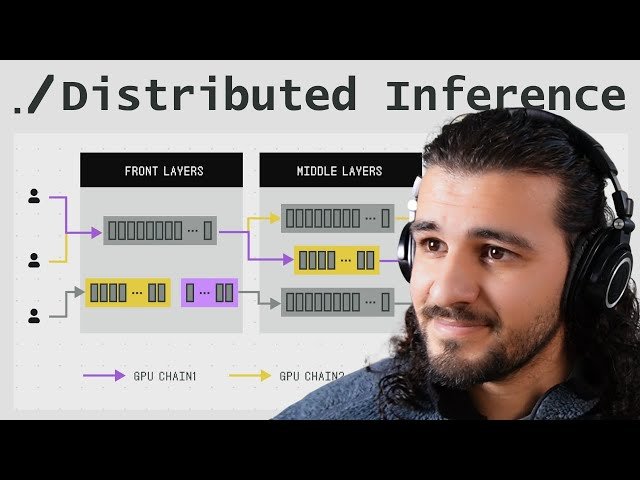
How to Serve Big LLM over Decentralized GPUs - Parallax and Dynamic Programming
Automatically move to the next video in the Classroom when playback concludes
